Kürzlich versuchte ich freudig mein neues Tablet (Odys Xelio, Android 4.0.3 ICS) mit dem VPN der Uni zu verbinden. Vom heimischen WLAN aus klappte das völlig problemlos. Die Probleme begannen an zwei anderen Orten: Dem Uni-WLAN und schließlich dem mobilen 3G-Netz. Also lief ich erstmal zu unserer Netzwerkabteilung, die aber nach eingehender Prüfung feststellte: Für Problem eins (Uni-WLAN) benutze ich den falschen – L2TP-basierten – Client, Problem zwei muss irgendwie am Tablet selbst oder am Provider liegen. Den Provider habe ich kontaktiert, wurde aber leider mit einer Standardantwort á la „müsste gehen, supporten wir aber nicht weiter, im Zweifelsfall ist Ihre Netzabteilung schuld“ abgefrühstückt. Also musste das google’sche Orakel befragt werden, mit dem Ergebnis: Sehr wohl blockieren einige Provider Punkt-zu-Punkt-Verbindungen auf einer ganzen Reihe von Ports, darunter vermutlich auch der Port, der für L2TP verwendet wird. Für Businesskunden werden diese dann natürlich auf Wunsch freigeschaltet. Nun, Businesskunde bin ich nicht, aber immerhin hatte ich nun für beide Probleme einen gemeinsamen Lösungsweg: Wechsel zum AnyConnect-Client, der VPN über den nicht geblockten Port 443 (SSL) bereitstellt. Im Google Play Store gibt es gleich mehrere kostenfreie Varianten des Clients. Die „AnyConnect ICS+“-Version, die ich zuerst getestet hatte, scheiterte an einem Berechtigungsproblem. Nun gut, zum Glück ist mein Tablet ja ab Werk gerootet, also als nächstes die Version „Rooted AnyConnect“ ausprobiert. Ergebnis: „Der TUN/TAP-Treiber konnte nicht geladen werden.“ Grummel… google… Aha, der genannte Treiber fehlt auf vielen Tablets, Abhilfe schafft man mittels „TUN.ko Installer“, ebenfalls bei Google Play erhältlich. Die Installation eines passenden TUN-Treibers war damit ganz einfach und siehe da, anschließend konnte sich auch AnyConnect aus jedem beliebigen Netzwerk heraus verbinden.
Kategorie: Allgemein
Neues im Bereich Software: Adobe Student&Teacher ESD Versionen und IBM SPSS Modeler Standortlizenz
Adobe Student&Teacher ESD Versionen im Softwareshop der Uni Köln
Durch eine Erweiterung des Adobe Vertrages sind im Online-Softwareshop der Universität zu Köln jetzt auch ESD (Electronic Software Download) Versionen der Adobe Student&Teacher Lizenzen verfügbar (zum Beispiel Photoshop, Indesign, Creative Suite).
Bestellen können alle Studierenden und Beschäftigten der Universität zu Köln (für die nicht-kommerzielle Privatnutzung).
Die Preise sind günstiger als die im Handel erhältlichen Student&Teacher Boxprodukte von Adobe.
Die Lizenzen sind für Windows oder Mac erhältlich, allerdings nur in der deutschsprachigen Version.
Die Adobe Student&Teacher ESD Versionen können im Softwareshop der Uni Köln bestellt und heruntergeladen werden.
Weitere Informationen zu Adobe Student&Teacher ESD an der Uni Köln
IBM SPSS Modeler Standortlizenz
Die Universität zu Köln nimmt am „IBM Mining in Academia“-Programm teil. Dieses beinhaltet eine kostenlose Standortlizenz für das Programm SPSS Modeler inkl. Text Analytics für 1 Jahr (bis 31.05.2013).
Die Software darf nur für Schulungszwecke und nicht-kommerziell orientierte wissenschaftliche Forschungszwecke auf Computern genutzt werden, die Eigentum der Universität zu Köln sind (Standortlizenz).
Die Software kann über den Softwareshop der Uni Köln heruntergeladen werden.
Ja, Gnome 3 ist die Pest. Aber ja, es ist heilbar.
Seit ein paar Monaten begrüßt mich allmorgendlich Gnome 3, auch „Gnome Shell“ genannt, als Desktop auf meinem LMDE (Linux Mint Debian Edition). Die Abneigung gegen diese Version, die ja niemand so schön formulieren kann wie Linus Torvalds höchstpersönlich, kann ich schon gut nachvollziehen. Im Grundzustand halte ich Gnome 3 ebenfalls für indiskutabel. Aber es dabei zu belassen, wäre einfach nicht zeitgemäß. Denn egal ob Browser, Handys oder CMS – letztlich kommt es darauf an, was man – mit vertretbarem Aufwand versteht sich – über die Nutzung von Erweiterungen aus dem System machen kann. Und da bietet Gnome 3 eine kleine, aber feine und vor allem sehr komfortabel installierbare Auswahl. Die zentrale Seite für Gnome-3-Erweiterungen ist hier zu finden:
Besucht man mit einem laufenden und halbwegs aktuellen (d.h. ab Version 3.2) Gnome diese Seite, kann man die dort angebotenen Erweiterungen auch gleich über den „On/Off“-Schalter in der Detailansicht der jeweiligen Erweiterung installieren und deinstallieren. Möchte man sich unabhängig von der Webseite einen Überblick über die aktuell installierten Erweiterungen verschaffen, empfiehlt sich die Installation des Gnome Tweak Tools, welches inzwischen bei Ubuntu, Linux Mint und Debian über die Standard-Repositories verfügbar ist.
Im Folgenden möchte ich einige Erweiterungen empfehlen, die aus meinem Gnome 3 wieder einen sehr schönen und komfortabel bedienbaren Desktop gemacht haben, ohne dass ich auf die Vorteile (ja, die gibt’s auch 😉 ) der neuen Version verzichten müsste:
- Frippery Bottom Panel – fügt eine Anwendungsleiste am unteren Bildschirmrand hinzu
- Frippery Panel Favorites – ergänzt Gnome 3 um eine Iconleiste mit den Lieblingsanwendungen („Schnellstartleiste“)
- Frippery Applications Menu – sorgt für die Rückkehr des Anwendungs- oder Startmenüs
Diese drei genügen aus meiner Sicht bereits, um Gnome 3 problemlos nutzbar zu machen. Alle nun folgenden Vorschläge sind kein Muss, sondern eher Geschmackssache:
- Frippery Move Clock – verschiebt die Uhr an den Rand der Titelzeile
- Frippery Shutdown Menu – fügt neben der „Suspend“-Funktion eine Option für echtes Herunterfahren hinzu
- AlternateTab – macht den Wechsel zwischen Anwendungen per „Alt-Tab“ wesentlich komfortabler
- Evil Status Icon Forever – bietet die Möglichkeit, Statusicons zurück in die Titelleiste zu holen (z.B. sehr sinnvoll für Pidgin)
Es gibt weitere, sehr nützliche Extensions, z.B. Statusmonitore, diverse Multimedia-Integrationen etc. Da kann man nur sagen: Viel Spaß beim Ausprobieren! Und selbstverständlich dürfen hier in den Kommentaren gerne weitere Empfehlungen gegeben werden.
Neues Blogfeature: SyntaxHighlighter
Vor allem die Kollegen aus dem Rechenzentrum fragten wiederholt nach einem Feature in der zentralen Bloginstallation, mit dem man Codeblöcke schöner darstellen kann. Daher wurde nun die Extension „SyntaxHighlighter Evolved“ bereitgestellt. Eine erste Anwendung sieht man im vorangegangenen Beitrag von Michael Lönhardt. Die Verwendung wird am besten auf der Projekthomepage beschrieben. Auf Wunsch kann die Erweiterung auch in anderen Blogs aktiviert werden. Wie man auf der allgemeinen Projekthomepage ebenfalls nachlesen kann, ist das Ganze nicht auf WordPress beschränkt, sondern kann mittels der dort bereitgestellten Dateien in jeder beliebigen Webseite integriert werden.
Rabatt auf Adobe Produkte bis 16. März 2012!
Studierende, Lehrer, Professoren und Schüler können jetzt dreifach sparen! Denn neben dem regulären Rabatt von bis zu 80% auf die Student and Teacher Editions gewährt Adobe ab sofort einen weiteren Preisnachlass von 50€ auf folgende Produkte:
- Adobe Creative Suite 5.5 Design Premium
- Adobe Creative Suite 5.5 Web Premium
- Adobe Creative Suite 5.5 Production Premium
- Adobe Creative Suite 5.5 Master Collection
Außerdem werden die Versandkosten erlassen.
Bitte vergiss mich nicht: USB-Stick-Reminder erinnert seinen Besitzer ans Mitnehmen
Es kommt oft genug vor, dass man als Benutzer im PC-Pool nach getaner Arbeit seinen Arbeitsplatz verlässt und dann nicht mehr an seinen noch angeschlossenen USB-Stick denkt.
Nicht immer ist der nachfolgende PC-Benutzer so fair und gibt den gefundenen Stick beim Fundbüro ab (im RRZK-B kann man dafür gerne die Mitarbeiter des Servicepoints oder den Nachtwächter ansprechen). Und schon ist die aktuelle Hausarbeit, die gerade heruntergeladene PDF-Datei oder die Bilder vom letzten Urlaub verloren.
Diesen Ärger kann man vermeiden, in dem man sich rechtzeitig beim Abmelden vom Rechner an seinen USB-Stick erinnern lässt. Der Kollege Andreas Hölz vom Netzwerk Medien hat da einen guten Tipp: Das Programm Flash Drive Reminder des Programmierers Brad Greco erinnert den Benutzer, wenn er unter Windows auf „Abmelden“ klickt, dass er bitte seinen USB-Stick entfernen solle. Das ganze funktioniert über eine Datei, die sich in den Autostart einbindet. Sie kann natürlich – falls der Autostart auf dem jeweiligen Rechner deaktiviert ist – auch manuell gestartet werden.
Es gibt zwei Varianten: Die Standardversion meldet sich bereits beim Starten der Datei und kann, wenn man es wünscht, automatisch ein Explorerfenster mit dem USB-Stick-Laufwerk öffnen. Die „Quiet Version“ hat diese Optionen nicht und bleibt die ganze Zeit still. Erst beim Abmelden öffnet sie ein Pop-Up mit dem entsprechenden Hinweis.
Die Qual der (Format-)Wahl: Online File Conversion Tools
So ein Pech! Da besucht einen ein Freund, Familienmitglied o.ä. und hat die Fotos seiner letzten Urlaubsreise in einer schönen Präsentation auf dem USB-Stick dabei, und als man die Datei auf seinem eigenen PC öffnen will, stellt man fest, dass es sich – „Ach ja! Ich hab das mit irgendsoeinem Programm auf ‘nem Mac erstellt!“ – um eine Datei im Keynote-Format handelt. Windows- und Linux-Betriebssysteme haben also keine Chance die Datei zu öffnen.
Wahlweise verlege man dieses Vorkommnis in den Veranstaltungsraum einer Tagung: Da hat man seinen Vortrag mit dem Programm „Pages“ auf einem Mac erstellt, aber es ist nun kein Mac in der Nähe, mit dem man die Datei öffnen und ausdrucken könnte… nota bene: Beide Formate – das Pages- und das Keynote-Format – können weder mit Powerpoint noch mit Word oder anderen gängigen Office-Programmen (OpenOffice, LibreOffice usw.) geöffnet oder konvertiert werden.
Die IT-affinen Leser wundern sich nun vielleicht oder halten diese Beispiele für arg konstruiert, aber: Solche Fälle treten (im Supportgeschäft) tatsächlich hin und wieder auf. Der Benutzer hat eine Datei, die er nirgendwo öffnen oder konvertieren kann – er kann sich selbst nicht helfen, weil er nicht weiß, wo und wie. Und so etwas trifft nicht nur Ausnahmsweise-Mac-User, sondern auch die, die vergessen/versäumt haben, die Datei zum Exportieren in ein anderes, gängigeres Austauschformat (PDF etc.) umzuwandeln.
In solchen Fällen, wo der eigene Computer oder der einer helfenden Person in der nächsten Umgebung nicht in der Lage ist, die entsprechende Datei zu konvertieren, können so genannte „Online File Conversion Tools“ helfen (an einer angenehm klingenden, sinnvollen Übersetzung dieser Bezeichnung ins Deutsche möge sich der Leser gern die Zähne ausbeißen). Man muss nicht mehr tun als eine Webseite aufrufen, die die Konversion einer ganzen Reihe verschiedener Formate ermöglicht. Im Folgenden werden einige solcher Onlinedienste vorgestellt:
Zamzar
Wer zum ersten Mal zamzar.com aufruft, wird zunächst von der Fülle der unterstützten Dateiformate erschlagen. Mehr Dateiformate bietet derzeit augenscheinlich kein weiterer entsprechender Dienst. Von Dokumentformaten und Grafiken über Musik und Videos bis hin zu ebook-Formaten, komprimierten Dateien (wie zip und bz2), ja sogar Auto-CAD-Dateien lässt sich dort eine Riesenpalette von Dateiformaten umwandeln.
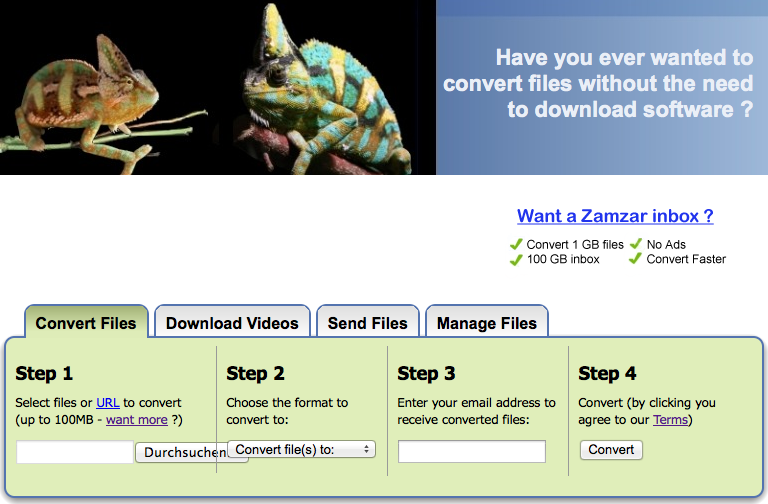 Wer spontan eine Datei konvertieren will, wird auf der übersichtlichen Seite durch die vier nötigen Schritte geführt: Man lädt seine Datei hoch (es werden alle kompatiblen Dateien bis zu einer Größe von 100 Megabyte angenommen), wählt im zweiten Schritt das entsprechende Zielformat aus, gibt in Schritt drei die E-Mail-Adresse an, zu der die dann konvertierte Datei gesendet wird. Im letzten Schritt muss der Benutzer den Terms of Service zustimmen…
Wer spontan eine Datei konvertieren will, wird auf der übersichtlichen Seite durch die vier nötigen Schritte geführt: Man lädt seine Datei hoch (es werden alle kompatiblen Dateien bis zu einer Größe von 100 Megabyte angenommen), wählt im zweiten Schritt das entsprechende Zielformat aus, gibt in Schritt drei die E-Mail-Adresse an, zu der die dann konvertierte Datei gesendet wird. Im letzten Schritt muss der Benutzer den Terms of Service zustimmen…
… die es aber in sich haben: Wer denkt, dass seine Dateien in irgendeiner Form verschlüsselt übertragen werden, irrt. Zumindest lässt sich ohne die kostenpflichtige Einrichtung eines Zamzar-Accounts (der einem außerdem bis zu einem Gigabyte Onlinespeicherplatz für seine konvertierten Dateien zur Verfügung stellt) gar nichts verschlüsseln. Nur der „Business-Dataplan“ (einer von drei verschiedenen Accounttypen) mit 49 Dollar/Monat bietet SSL-verschlüsselte Übertragung (128 bit). Die Datei selbst kann aber nicht verschlüsselt werden. Laut den Terms of Service kontrolliert das Unternehmen die konvertierten Dateien nicht auf deren Inhalt. Aber ob und – wenn ja – wie neugierig die Firma Zamzar, die ihre Server in den USA stehen hat, nun wirklich ist, kann man nur mutmaßen.
Youconvertit
Das sich noch im Beta-Stadium befindende Youconvertit unterstützt ebenfalls eine Reihe von Formaten, und auch dort wird dem User die konvertierte Datei per E-Mail zugesandt. Außerdem stellt der Dienst einen gesonderten Bereich zur Konvertierung von Youtube- und anderen Online-Videodiensten bereit. Hierzu muss nur der Link zum gewünschten Video angegeben werden. Nach einem Klick auf „Download it“ wird einige Sekunden später das umgewandelte Video zum Download bereitgestellt. Der User hat Auswahlmöglichkeit zwischen 3GP-Filmen in niedriger Qualität (geeignet für Handys und Smartphones), Flash-Videos in geringer und mittlerer Qualität sowie MP4-Dateien. Auch der WEBM-Standard wird unterstützt.
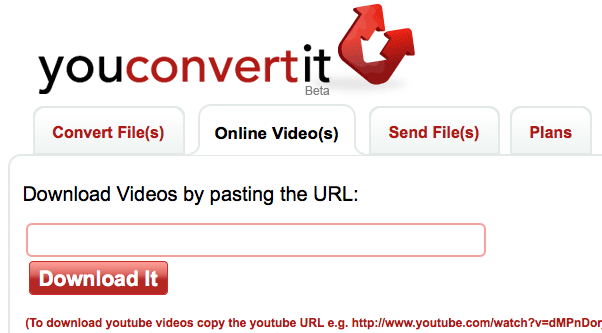 Hinweis: In Deutschland aus Lizenz- und Rechtsgründen nicht erreichbare Videos können über die youconvertit-Seite nicht geladen werden.
Hinweis: In Deutschland aus Lizenz- und Rechtsgründen nicht erreichbare Videos können über die youconvertit-Seite nicht geladen werden.
Im Vergleich mit anderen Video-Convert-Websites ist das Angebot von youconvertit nicht unbedingt herausragend. Im Bereich Video-Download bieten viele andere Dienste – darunter z.B. video2mp3.net oder filsh.net – sehr viel mehr. Das gilt auch für die Menge der anderen unterstützten Dokument-, Grafik- oder Musikformate: youconvertit schneidet eher durchschnittlich ab. Auch gibt es dort keinerlei Verschlüsselungsmöglichkeit – auch nicht nach Bezahlung. Immerhin unterstützen die kostenpflichtigen Premium-Accounts Dateigrößen von bis zu einem Gigabyte.
Online Convert
Dieser Dienst stellt die konvertierten Dateien für 24 Stunden zum Download zur Verfügung. Nach dieser Frist – oder nachdem die Datei zehnmal heruntergeladen wurde – wird die Datei automatisch gelöscht und steht nicht mehr zum Download bereit.
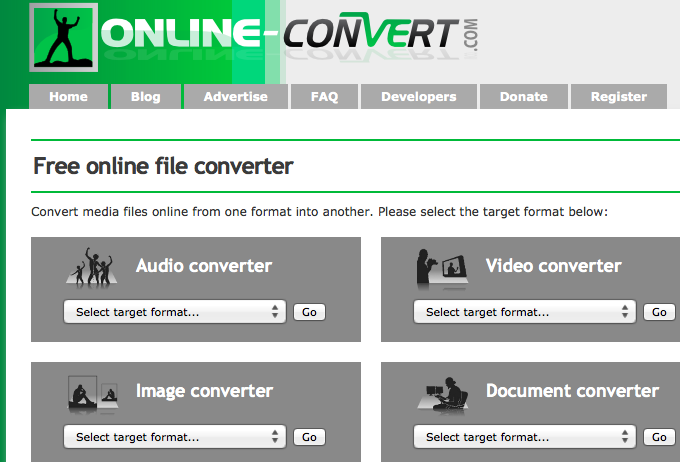 Bei online-convert.com gibt es erfreulich viele Parameter, die sich einstellen lassen. Beispielsweise im Bereich Musik-Dateien: So ist bei der Umwandlung in eine MP3-Datei die Bitrate von 8 bis 320 kbps konfigurierbar – wünschenswert wäre, wenn dort auch VBR zur Auswahl stünde.
Bei online-convert.com gibt es erfreulich viele Parameter, die sich einstellen lassen. Beispielsweise im Bereich Musik-Dateien: So ist bei der Umwandlung in eine MP3-Datei die Bitrate von 8 bis 320 kbps konfigurierbar – wünschenswert wäre, wenn dort auch VBR zur Auswahl stünde.
Interessant: Nach der Konversion wird auf der entsprechenden Webseite ein QR-Code bereitgestellt, der einen Link zur Downloadseite enthält: eine einfache Möglichkeit zur Weitergabe der Datei – natürlich wird man dort (wie auch bei anderen Online Conversion Diensten) darauf hingewiesen, dass man mit dem Teilen der Datei keine Urheber- oder sonstigen Rechte verletzen darf.
Verschlüsselungsmöglichkeit mit 256 bit für Up- und Download erhält man auch dort gegen Geld. Schön ist, dass dort kein besonders teurer Kontrakt abgeschlossen werden muss, sondern der Nutzer mittels eines fünf Dollar teuren „24-Stunden-Passes“ kurzfristige Möglichkeit zur Verschlüsselung hat. Weiterhin ist nach dem Kauf des 24-Stunden-Passes die Grenze der Dateigröße von 100 Megabyte auf 800 MB angehoben.
Interessant ist bei diesem Dienst die Möglichkeit zur Integration der online-convert.com-Dienste in die eigene Webseite. Sogar eine „File converter API“ inklusive Dokumentation steht dort bereit.
Free File Converter
 Der Anbieter des Free File Converter kennt sich der Selbstbeschreibung nach besonders gut mit Nachrichten-Webseiten aus: Er ermöglicht das Konvertieren und den Download von Videos beispielsweise von spiegel.de oder auch von guardian.co.uk. Auch stehen dem Nutzer eine umfangreiche Liste weiterer Formate zur Verfügung. Leider kann man – natürlich bis auf das Ausgabeformat selbst – keinen Einfluss auf Ausgabequalität, Bitrate oder ähnliche Einstellungen nehmen. Auch in sonstiger Hinsicht hat dieser Dienst nicht allzuviel zu bieten – außer, dass er sich die Konversion von Videos dieser Nachrichtenseiten auf die Fahnen schreibt.
Der Anbieter des Free File Converter kennt sich der Selbstbeschreibung nach besonders gut mit Nachrichten-Webseiten aus: Er ermöglicht das Konvertieren und den Download von Videos beispielsweise von spiegel.de oder auch von guardian.co.uk. Auch stehen dem Nutzer eine umfangreiche Liste weiterer Formate zur Verfügung. Leider kann man – natürlich bis auf das Ausgabeformat selbst – keinen Einfluss auf Ausgabequalität, Bitrate oder ähnliche Einstellungen nehmen. Auch in sonstiger Hinsicht hat dieser Dienst nicht allzuviel zu bieten – außer, dass er sich die Konversion von Videos dieser Nachrichtenseiten auf die Fahnen schreibt.
Fazit
Wer dringend eine Datei benötigt, sie aber nicht mit den auf seinem Computer installierten Programmen öffnen kann, kann die Online-Konversions-Dienste gezielt nutzen, um die Dateien in ein gewünschtes Format umzuwandeln. Aus Sicht des Datenschutzes gilt aber für sämtliche Dienste das gleiche Problem: Genau wie bei Online-Storage-Diensten wie Dropbox u.ä. weiß der Nutzer nicht, was genau mit seinen Daten geschieht. Die Dateien landen auf – meist in den USA ansässigen – Servern, und was genau nun von Seiten des Anbieters mitgelesen werden kann/wird, kann man nur mutmaßen. Außer Zamzar äußert sich keiner der beschriebenen Dienste über die Sicherheit seiner Daten, und auch Zamzar bleibt bei seinen Angaben in den Terms of Service recht vage. Bis auf den Übertragungsweg ist von Verschlüsselung keine Rede.
Mit anderen Worten: Man muss sich im Klaren sein, dass man seine zu konvertierenden Dateien mit einer Firma teilt. Was mit den Daten passiert, weiß man nicht. Bevor man also seine Steuererklärung oder die letzte Telefonrechnung (samt Einzelverbindungsnachweis) dort in ein anderes Format umwandeln lässt, sollte man sich fragen, ob man nicht doch auf die herkömmliche Art und Weise vorgehen will: „OpenOffice“ ist ein gutes Werkzeugt für die Konversion von Textdateien/Dokumenten – inklusive PDF-Export, das kostenlose „Free Studio“ dient zum umwandeln vieler Arten von Musik- und Videodateien. Und die Freeware „Gimp“ öffnet und speichert eine ganze Reihe von Grafikdateien.
Ein Problem hat man nur, wenn man seine Dokumente z.B. mittels der Mac-Programme „Pages“ und „Keynote“ erstellt hat: Die damit erstellten Dokumente lassen sich ausschließlich aus diesen Programmen heraus exportieren – z.B. als Word-, Powerpoint- oder PDF-Datei.
Ist aber ein solches Programm nicht vorhanden oder hat man keine datenschutztechnischen Bedenken, können Online-Konversions-Dienste eine schnelle und spontane Hilfe sein. Das oben zuerst genannte Zamzar erscheint wegen seiner vielen unterstützten Dateiformate als die beste Wahl.
Der RRZK-Blog an neuer Stelle. In schön. Und Farbe. Und bunt.
Der RRZK-Blog ist umgezogen, und zwar in die WordPress Installation in der auch alle anderen Blogs liegen. So sparen wir etwas Administrationsaufwand.
Außerdem ist euch bestimmt der neue Look aufgefallen. Das neue Thema basiert technisch auf dem offiziellen TwentyEleven Theme und visuell auf dem neuen Corporate Design der Uni Köln. An dieser Stelle vielen Dank an Martin Boenigk, der hier die meiste Arbeit geleistet hat!
Wie gefällt es Euch? Habt ihr Verbesserungsvorschläge? Klappt alles fehlerfrei? Zu bunt? Nicht bunt genug? (BTW: Mehrfarbigkeit gibt es nur in aktuellen Browsern, da CSS3)
Schöner neuer Kernel
Linus Torvalds erfreut uns in diesen Tagen mit dem Kernel 3.x, der bei nahezu allen Desktop-Linuxen inzwischen in den Repos bereitsteht. Das Upgrade hat für mich und meinen Dell-Laptop zwei ärgerliche Probleme mitgebracht, die ich inzwischen zumindest halbwegs lösen konnte. Da an der Uni wohl noch ein paar andere darüber stolpern werden, hier meine Hinweise:
- OpenAFS: Seit Kernel 2.6.39 wird der AFS-Client 1.4.x nicht mehr unterstützt, man ist zum Update auf 1.6.x gezwungen. Dieser lag bis vor wenigen Tagen noch in einer Pre-Version vor, inzwischen ist er als stable markiert. Die Doku ist nach wie vor ein Traum, sodass mir spontan niemand erklären konnte, warum ich plötzlich auf keine RRZK-Volumes mehr zugreifen konnte. Nach langem Testen konnte ich das Ganze nun auf Firewall-Probleme zurückführen. Weitere Eingrenzung war mir noch nicht möglich, da selbst bei eingetragener Freigabe der erste Zugriff nach laaaanger Zeit in einem Timeout endet. Erst ab dem zweiten Zugriff geht’s dann wieder flott.
- Suspend: Nach dem Update auf Kernel 3.0 krachte mein Laptop (Dell Latitude E4300) bei jeglichen Suspend-Versuchen zusammen. Auch hier musste ich lange suchen, um den Schuldigen zu finden. Schließlich konnte ich das „mac80211“-Modul, welches für WLAN zuständig ist, als Ursache identifizieren. Da scheint sich ein Bug eingeschlichen zu haben (siehe auch diesen Hinweis), den man entweder wie im Link angegeben patchen oder weiträumig umgehen kann. Dazu genügt das Anlegen der Datei
/etc/pm/config.d/unload_modules
mit dem Inhalt
SUSPEND_MODULES="$SUSPEND_MODULES mac80211"
Zumindest Suspend-to-RAM (a.k.a. „Bereitschaft“) klappt danach bei mir problemlos, Suspend-to-Disk (a.k.a. „Ruhezustand“) klappt zwar zunächst ebenfalls, das Aufwachen endet jedoch leider in einem normalen Systemstart. Da ich s2disk jedoch eh fast nie verwende, verfolge ich das nicht weiter. Kommentare mit der Lösung sind natürlich dennoch erwünscht. 😉
CSS neu laden, ohne die Webseite neu laden zu müssen…
Mit dem Add-on CSS Reloader kann man im Firefox, den CSS-Code einer Webseite neu laden, ohne den HTML-Code neu laden zu müssen.
Wer Webseiten erstellt und an dem Punkt angekommen ist, an dem das Fine-Tuning des CSS-Codes beginnt, kennt das Problem:
Eigentlich will man nur schauen, ob die jüngste Anpassung den gewünschten Effekt hatte aber beim Drück auf F5 muss man die ganze Seite neu laden, PHP-Skripte müssen gestartet werden, Datenbanken abgefragt usw.
Einfacher können es nun Benutzer des Firefox-Browsers haben: Mit dem Add-on „CSS Reloader“.
Einfach installiert, lädt er beim Druck auf F9 lediglich das CSS einer Seite neu, ohne den HTML-Code neu abzufragen.
Das Add-on kann man hier herunterladen: https://addons.mozilla.org/en-US/firefox/addon/46211/