In meinem letzten Artikel habe ich mit einem Beispiel beschrieben, wie man mittels Puppeteer automatisert Screenshots von Websites erstellt. Das Problem stellte sich für uns, weil wir im großen Umfang CMS-Unterseiten auf Frontend-Probleme nach einem Upgrade testen wollten.
Ziel war es, ein Skript zu erstellen, welches vor einem Upgrade gestartet werden kann und zunächst den Status Quo von Websites in Screenshots festhält.
Nachdem die Upgrades an den Websites durchgeführt wurden, kann das Skript erneut gestartet werden und es werden automatisch visuelle Vergleichtests durchgeführt.
Test-Logik
Zum Ablauf der Visual Regression Tests habe ich folgende kleine Test-Logik entwickelt:
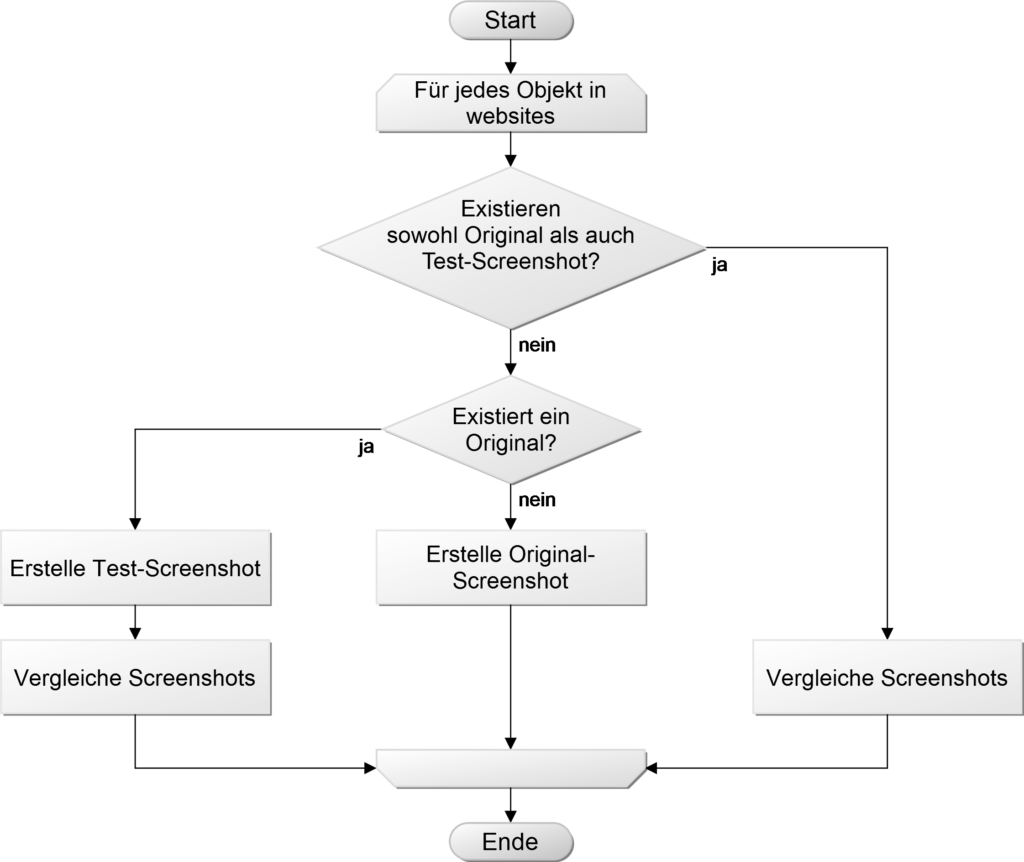
Wenn ich keinen Screenshot finde, erstelle ich einen für einen späteren Vergleich. Finde ich einen vor, dann erstelle ich einen neuen und vergleiche ihn direkt.
Visual Regression Testing mit Puppeteer und Resemble.js
Um den obigen Test-Algorithmus abzubilden, muss die app.js aus meinem letzten Artikel um eine Testschleife, die zusätzliche Library Resemble.js und das File System-Modul von Node.js erweitert werden.
Die folgende Vorgehenswiese lässt sich auch anhand meiner Commits im Github-Repository nachverfolgen.
Dateizugriff einrichten
Für den Zugriff auf das Dateisystem stellt Node.js das fs-Modul bereit. Damit lassen sich klassische Dateioperationen durchführen (copy, move etc.).
Um das Modul zu verwenden, muss es mittels require in der app.js eingebunden werden:
const fs = require('fs')
Bisher war der Pfad- und Dateiname der Screenshots, die in der takeScreenshot()-Funktion erstellt werden noch hard coded. Weil die Funktion zukünftig sowohl Vorher- als auch Nachher-Screenshots festhalten soll, werden folgende Änderungen vorgenommen:
const screenshotsFolder = './screenshots/'
und
await page.screenshot({ path: filename, fullPage: true })
Test-Logik aufbauen
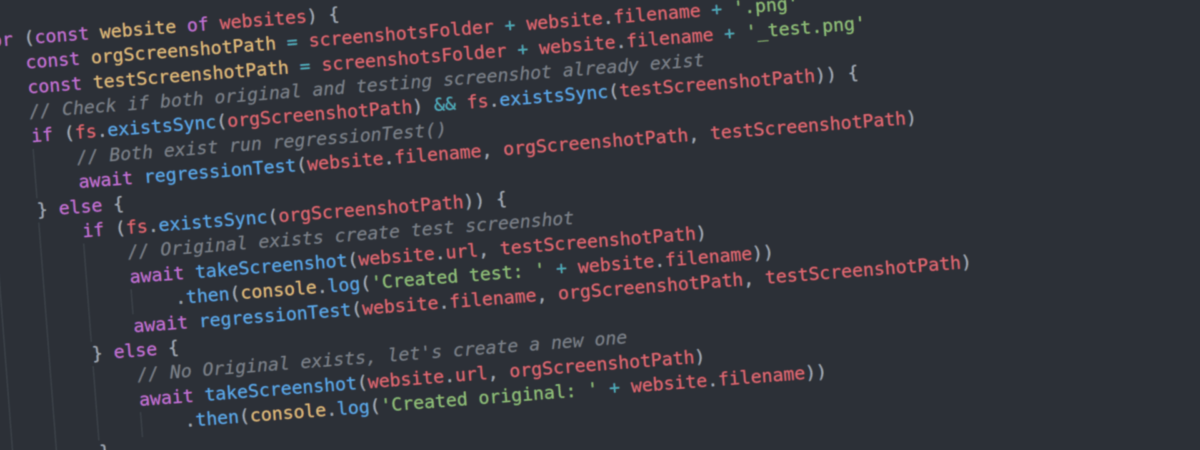
Jetzt kann die eigentliche Test-Logik aufgebaut werden. Ziel ist es, die Screenshots noch nicht zu vergleichen, aber schon die nötige Schleife zusammenzubasteln. Ich habe dafür eine Funktion erstellt, welche den Test startet. Hierfür eignet sich in diesem Fall die Verwendung der Immediately-invoked Function Expression.
Die Immediately-invoked Function Expression ist eine Möglichkeit, Funktionen sofort auszuführen, sobald sie erstellt werden:
(() => {
/* Befehle */
})()
Unsere asynchrone Funktion sieht dann so aus:
// Immediately-invoked arrow function after launch
(async () => {
// Create screenshots folder if it does not exist
if (!fs.existsSync(screenshotsFolder)) {
fs.mkdir(screenshotsFolder, (err) => {
if (err) throw err
})
}
for (const website of websites) {
const orgScreenshotPath = screenshotsFolder + website.filename + '.png'
const testScreenshotPath = screenshotsFolder + website.filename + '_test.png'
// Check if both original and testing screenshot already exist
if (fs.existsSync(orgScreenshotPath) && fs.existsSync(testScreenshotPath)) {
// Both exist run regressionTest()
} else {
if (fs.existsSync(orgScreenshotPath)) {
// Original exists create test screenshot
await takeScreenshot(website.url, testScreenshotPath)
.then(console.log('Created test: ' + website.filename))
// run regressionTest()
} else {
// No Original exists, let's create a new one
await takeScreenshot(website.url, orgScreenshotPath)
.then(console.log('Created original: ' + website.filename))
}
}
}
})()
Mit fs.existsSync() wird geprüft, ob eine Datei unter dem angegeben Pfad existiert. Dies könnte auch mittels Promises/await asynchron und ohne Callbacks gemacht werden (Momentan noch experimental).
Vergleichen von Screenshots mit Resemble.js
Jetzt fehlt nur noch die regressionTest()-Funktion, damit wir unsere Tests durchführen können.
Hierfür muss zunächst Resemble.js mittels npm installiert und eingebunden werden:
$ npm install resemblejs --save
In unserer app.js:
const resemble = require('resemblejs')
Die asynchrone regressionTest()-Funktion sieht wie folgt aus:
const regressionTest = async (filename, orgScreenshotPath, testScreenshotPath) => {
console.log('Visual Regression: ' + filename)
const diffFolder = screenshotsFolder + 'diff/'
resemble(orgScreenshotPath).compareTo(testScreenshotPath).onComplete(data => {
if (data.misMatchPercentage > 0) {
console.log('Missmatch of ' + data.misMatchPercentage + '%')
// Create screenshots/diff folder only when needed
if (!fs.existsSync(diffFolder)) {
fs.mkdir(diffFolder, (err) => {
if (err) throw err
})
}
// Set filename and folder for Diff file
const diffScreenshotPath = diffFolder + filename + '_' + data.misMatchPercentage + '_diff.png'
fs.writeFile(diffScreenshotPath, data.getBuffer(), (err) => {
if (err) throw err
})
}
})
}
Die Funktion erhält die Parameter filename aus dem websites-Array, sowie den zusammengesetzten Pfad zum Original. Dazu kommt ein Vergleichsscreenshot (orgScreenshotPath, testScreenshotPath).
Diese werden nun durch resemble verglichen:
resemble(orgScreenshotPath).compareTo(testScreenshotPath)
Wenn ein Unterschied zwischen orgScreenshotPath und testScreenshotPath besteht wird eine Differenzgrafik erstellt. Diese zeigt standardmäßig die Unterschiede in Magenta an. Damit Fehler schneller gefunden werden können, werden diese Differenzbilder im Unterverzeichnisscreenshots/diff abgelegt.
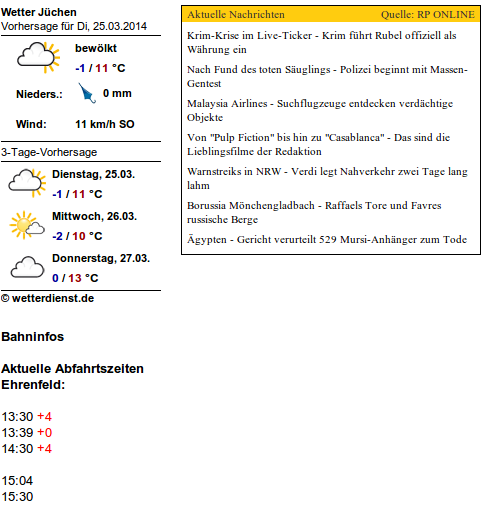
In folgenden Screenshots fehlen Seiteninhalte. Resemble.js findet den Unterschied und stellt ihn gut sichtbar dar:

Schneller Vergleichen von einzelnen Screenshots
Wenn eine einzelne URL verglichen werden soll, ist es etwas mühselig diese immer in das websites-Array in app.js einzufügen. Deshalb habe ich in dem Skript die Möglichkeit ergänzt, beim Aufruf URL(s) als Kommandozeilenargumente anzuhängen:
$ node app.js https://rrzk.uni-koeln.de/
let websites = []
process.argv = process.argv.slice(2) // Slice away the first two command line arguments
if (process.argv.length == 0) {
// If no command line arguments are given add hardcoded examples
websites = [
{ url: 'https://rrzk.uni-koeln.de/', filename: 'homepage' },
{ url: 'https://rrzk.uni-koeln.de/aktuelles.html', filename: 'news' },
{ url: 'https://typo3.uni-koeln.de/typo3-angebote.html', filename: 'typo3-offerings' },
{ url: 'https://typo3.uni-koeln.de/typo3-links-und-downloads.html', filename: 'typo3-links-and-downloads' }
]
} else {
process.argv.forEach((val, index) => {
try { // Check if argument is a URL
let screenshotURL = new URL(val)
// Add URL to websites array if valid and create filename
websites.push({ url: screenshotURL.href, filename: index + '_' + screenshotURL.host})
} catch (err) {
console.error('"' + val + '" Is not a valid URL!')
}
})
}
Mittels der Klasse URL, wird die Zeichenkette in ein URL-Objekt konvertiert. Wenn dies fehlschlägt, enthält die Zeichenkette keine gültige URL.
Das finale app.js-Skript:
Das finale app.js Skript ist nun fertig app.js Download
Zum Starten einfach app.js ausführen: $ node app.js.
Wenn Screenshots von einzelnen Websites verglichen werden sollen, kann dies folgendermaßen gemacht werden:
$ node app.js https://rrzk.uni-koeln.de/
Created test: 0_rrzk.uni-koeln.de
Visual Regression: 0_rrzk.uni-koeln.de
Missmatch of 58.22%
Ausführen mittels Docker
Dieses Skript kann auch in einer containerbasierten Umgebung ausgeführt werden. Als Basis-Image verwende ich zenato/puppeteer. Das Image enthält einen standardisierten „Chrome“-Browser und stellt eine Umgebung bereit, in der Screenshots in konsistenter Weise erstellt werden.
Mein Dockerfile dafür sieht so aus:
FROM zenato/puppeteer:latest
USER root
COPY package.json /app/
COPY app.js /app/
RUN cd /app && npm install --quiet
WORKDIR /app
ENTRYPOINT [ "node" , "app.js" ]
Image erstellen:
$ docker build -t movd/puppeteer-resemble-testing:latest .
Container ausführen:
$ docker run --rm -v "${PWD}/screenshots:/app/screenshots" movd/puppeteer-resemble-testing:latest http://example.com
Das Image kann auch direkt vorgebaut von „Docker Hub“ geladen werden:
$ docker pull movd/puppeteer-resemble-testing:latest
Die hier erstellte Lösung basiert auf den Anforderungen im RRZK. Ich freue mich über Feedback und weitere Use-Cases, weil die Test-Logik eine einfache Schleife ist, ließe sich diese auch für andere Testreihenfolgen anpassen. Resemble.js ließe sich auch besonders gut in automatisierte Test mit Mocha oder Jest verwenden.