Beim Surfen im Web begegnet man heutzutage quer durch die Bänke der verschiedenen Browser und Betriebssysteme einigem, das das angenehme Surfen erschwert: Entweder nerven Cookie-Banner, man wird über sämtliche Webseiten mit der immer gleichen Werbung bombardiert und im Hintergrund sammeln Google und Co. fleißig Daten über unsere Webseitenbesuche oder Online-Käufe.
In diesem Beitrag geht es um folgende Fragen:
- Wie kann man „sicher“ surfen, ohne dass Daten über mich und mein Surfverhalten abfließen?
- Was kann ich tun, um trotzdem einigermaßen bequem zu Surfen, ohne von Cookiewarnungen gestört zu werden? Und:
- Wie bekommt man das Blockieren von Cookies in den Griff, ohne dass mein Browser die Webseiten vor lauter Datenschutzeinstellungen nicht mehr richtig anzeigen kann (bespielsweise weil im Hintergrund die nötigen Funktionen zur Anzeige blockiert werden)?
Die c’t hat sich mit diesen Themen auch vor einiger Zeit beschäftigt. Hier versuchen wir, mit noch etwas weniger Aufwand möglichst viel zu erreichen und gehen dabei möglicherweise nicht ganz so weit wie die c’t.
Worum es hier nicht geht
Natürlich gibt es weitere Themen, die ebenso beachtenswert sind, wie beispielsweise „Das absolut sichere Betriebssystem fürs Online-Banking“ oder sehr effektive Skript-Blocker wie NoScript – eines der wirkungsvollsten Tools beim Blockieren von Webinhalten, aber auch eines der am schwierigsten zu bedienenden Tools, wo täglich viel Handarbeit beim Surfen nötig ist. Aber: Geht man so tief, dann bewegt man sich erstens an den Grenzen dessen, was man einem „normal-IT-informierten“ Menschen zumuten kann. Das ist also nur in den seltensten Fällen etwas, das man seinen Eltern empfehlen oder gar einstellen mag.
Zum anderen soll es hier ja um bequeme Lösungen gehen, die alltagstauglich und für alle schnell umsetzbar sind.
Auch das anonyme Surfen ist nicht Ziel dieser Betrachtung.
Der richtige Browser
Bei der Browser-Wahl ist man immer am Rande der Gretchenfrage: Wie hast Du’s mit dem Webbrowser? Firefox? Chrome? oder gar: Edge? Sicherlich kann man die Entscheidung, welches Programm man nutzt, guten Gewissens als Geschmacksfrage betrachten. Objektiv gesehen gibt es Browser, die privacyfreundlicher sind als andere. Erst vor kurzem gab es in der c’t 14/2021 vom heise-Verlag einen Browsertest dazu, siehe hier. Der eigentliche Test in der Onlinefassung befindet sich leider hinter einer Paywall, aber an der Überschrift lässt sich schon das Ergebnis erahnen: Vorne liegen der Brave-Browser (auf dem Google-freien Chromium-Browser basierend), dicht gefolgt von dem bekannten Mozilla Firefox und der Apple-Browser Safari.
Würde man eine Empfehlung aussprechen, ist der Brave-Browser ohne weitere Einschränkungen zu empfehlen. Will man aber noch einige Add-Ons einsetzen, die das bequeme, privacy-bewusste Surfen wirksam unterstützen, hat der Firefox die Nase vorn. Es gibt sicherlich auch für Chrome/Chromium/Brave gute Erweiterungen, aber hier legen wir den Fokus auf den Mozilla-Browser – wobei viele der hiesigen Erweiterungsempfehlungen sowohl für den Firefox als auch für chromium-artige Browser verfügbar sind.
Damit gibt es auch eine klare Warnung vor dem von Google entwickelten Chrome-Browser: Hier werden sämtliche Websuchen, Google-Ergebnisse und aufgerufene URLs mit Google geteilt. <ironie>Falls Sie als Chrome-User:in also mal vergessen haben sollten, auf welcher Webseite Sie dies oder jenes gefunden hatten: Einfach mal bei Google nachfragen, dort wissen sie das sicherlich noch.<ironie /> Bei Chromium und bei Brave ist dies nicht der Fall. Zudem avisiert Google seinen User:innen, dass es zukünftig jegliche Erweiterungen, die die Übermittlung von Werbeanzeigen einschränken, nicht mehr zulassen will.
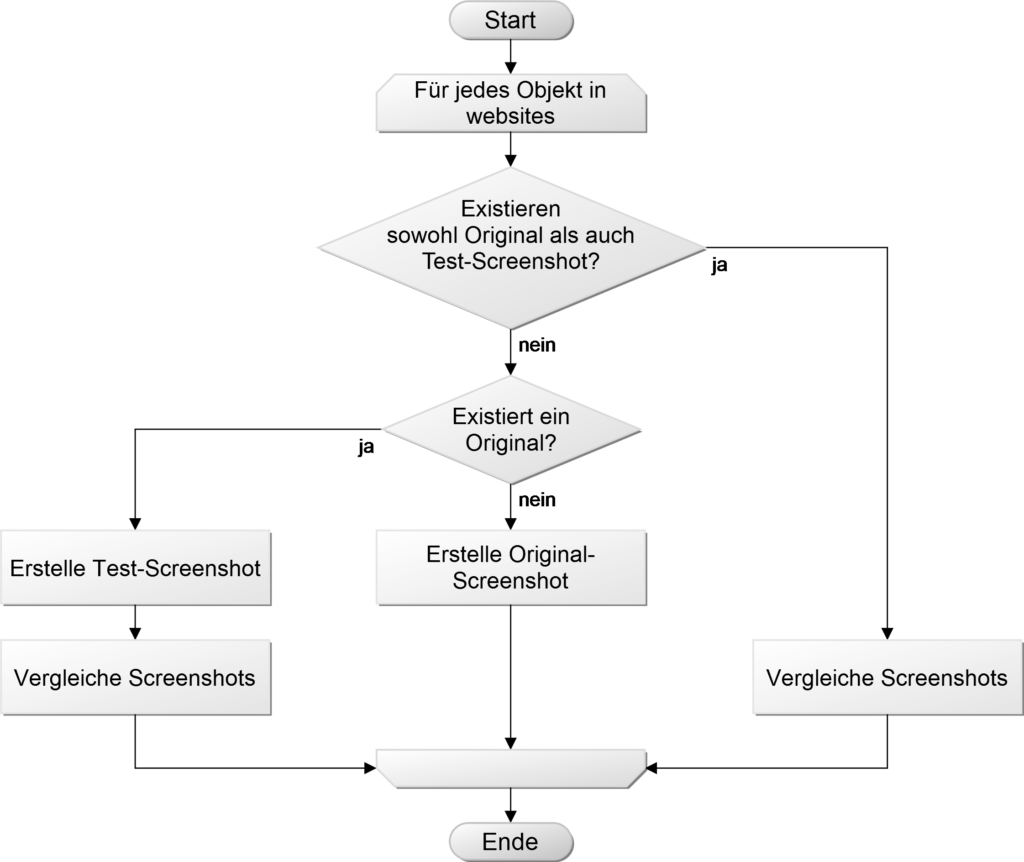
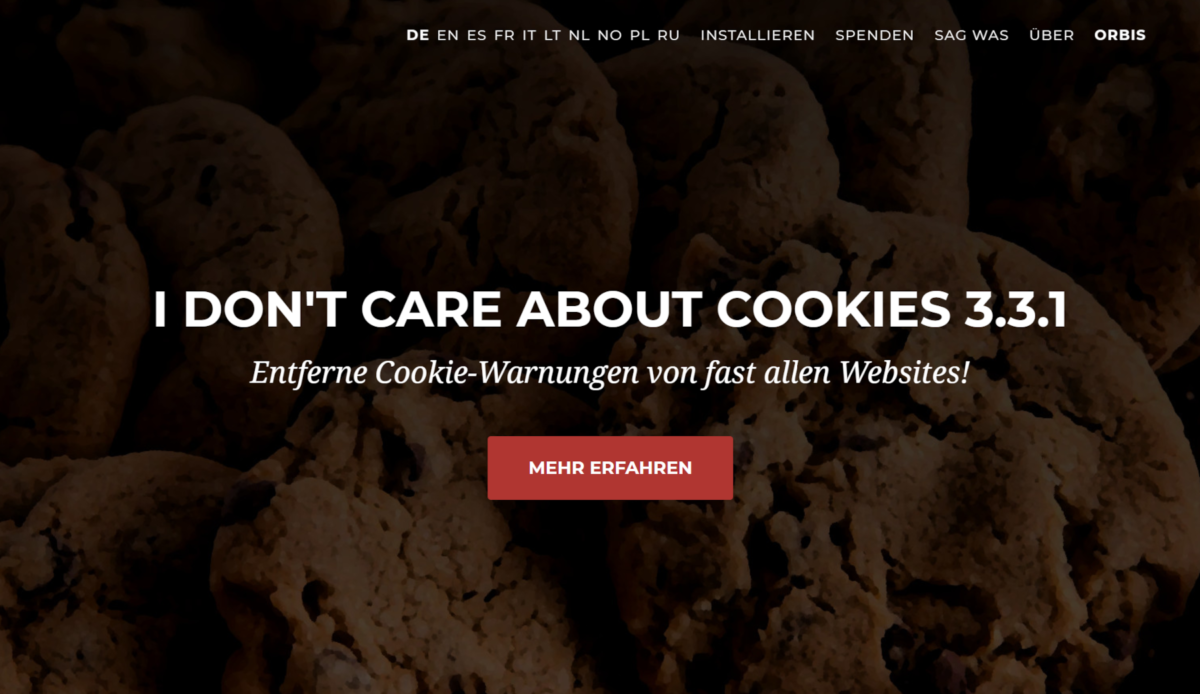
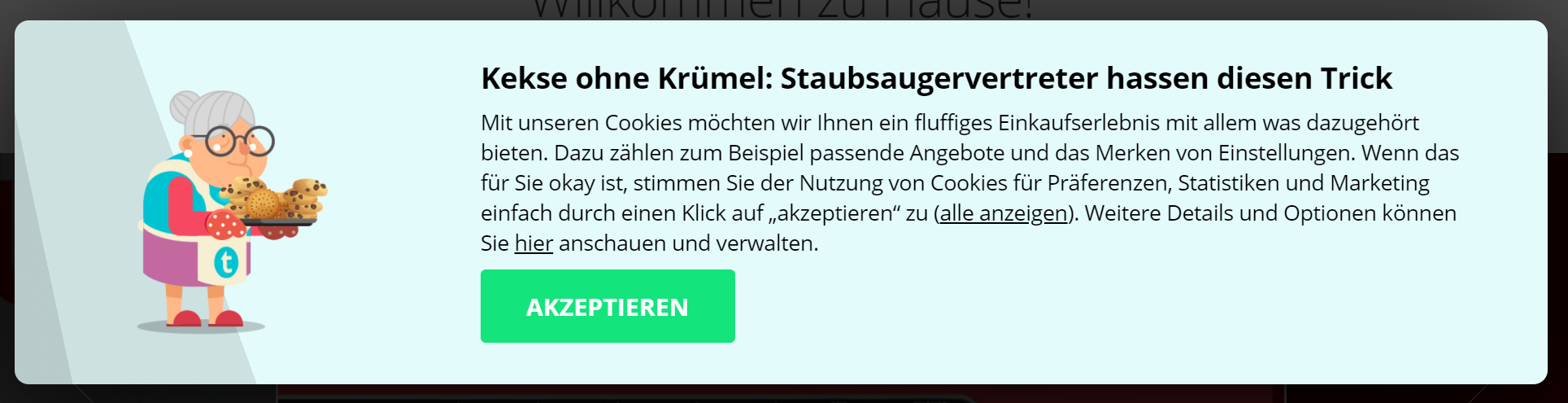
Kekse ja/nein und wenn ja, wie viele? Cookie-Banner blockieren
Wer es satt ist, bei jeder neuen Seite die Bestätigung für mehr oder weniger Cookies geben zu müssen, und sich darüber zu ärgern, dass die Banner fast alle unterschiedlich aussehen (und wo war jetzt nochmal die Funktion zum Konfigurieren, wie viel Cookies was an welche Firma weitergeben?), dafür ist das Add-on „I don’t care about Cookies“ geeignet. Nicht ausnahmslos, aber doch in einem größeren Anteil werden sämtliche Cookie-Banner im Hintergrund ohne menschliches Zutun „beantwortet“. Dies jeweils möglichst privacyfreundlich. Wer mag, kann bei fehlgeschlagenen Cookiebannerblockierungsversuchen die URL an den Betreiber übermitteln, in der Hoffnung, dass zukünftig auch diese URL cookie-banner-frei sein wird.
Cookies automatisiert löschen
Der Firefox bringt von sich aus einige cookie-freundliche Einstellungen mit, die man unter den Einstellungen findet. Werden dort Cookies generell blockiert, kann das zu Problemen beim Surfen führen, gerade dann, wenn man beispielsweise bei Webshops eingeloggt ist. Sicherlich ist der Inkognitomodus hier auch eine Möglichkeit, aber wenn man „einfach nur“ möchte, dass nach dem Besuch einer Webseite das dazugehörige Sessioncookie und andere gelöscht werden, leistet dies das Add-on „Cookie Auto-Delete“ (für Firefox und Chrome/ium). Dies lässt sich außerdem konfortabel einstellen, wo wann und in welcher Frequenz Cookies nach Webseitenbesuchen gelöscht werden sollen.
Übermittlung von Daten an Drittanbieter überwachen/deaktivieren
Wissen Sie, wer im Hintergrund eigentlich mitliest, wo und auf welchen Seiten Sie surfen? Das zu analysieren kann schon mal zu überraschenden Erkenntnissen führen. Dazu brauchen Sie das Add-on uBlock origin. Dies gibt es ebenfalls für Firefox und Chrome/ium.
Wenn Sie es ausprobieren wollen, gehen Sie einmal auf die Webseite der Süddeutschen Zeitung oder noch besser: dem Spiegel und schauen Sie, wo die Daten hinfließen! Übrigens: Bei der Zeit besteht übrigens die spannende Option, sich von der Datenübermittlung freizukaufen, für ein paar Euro pro Woche…
Ebenso wirkungsvoll ist der „Privacy Badger„. Hier eine Entscheidung zu fällen, ob uBlock oder der Privacy Badger seine Dienste besser leistet, ist schwer abzuwägen. Beide Add-ons lassen sich bestens nebeneinander betreiben, und meistens werden beide Erweiterungen „fündig“.
Werbung blockieren
Auch das Ermitteln von Werbeanzeigen und das Eintragen in eine Blocklist erledigt das uBlock Origin. Zudem werden Übermittlungen von Webseiten, die bekanntermaßen Schadsoftware verteilen, wirkungsvoll blockiert.
AdBlock Plus ließe sich unter Umständen auch als Werbeblocker verwenden, wobei in den letzten Jahren bekannt wurde, dass bestimmte Werbeeinblendungen bewusst durchgelassen wurden. Offiziell heißt es „einige, nicht aufdringliche Werbung„. Jedoch gab es in der Vergangenheit gewisse Verdachtsmomente, dass sich Werbetreibende auf eine Allowlist einkaufen konnten. Hierzu sei auch auf ein Gerichtsurteil hingewiesen.
Ganz abzuraten ist von AdBlock Plus also nicht. Aber uBlock origin erfüllt sehr ähnliche Zwecke, und zwar sehr wirkungsvoll, so dass die Empfehlungstendenz hier eher in Richtung uBlock geht.
Noch etwas zur Suchmaschinennutzung
Viele Webinhalte sind so ausgelegt, dass die Datenkrake Google sie möglichst gut finden kann. Die Technik der Search Engine Optimization („SEO“) macht leider dort Halt. Beispielsweise schafft es die deutlich datenschutzfreundlichere Suchmaschine duckduckgo.com nicht, sämtliche Inhalte der uni-koeln.de-Webseiten auszulesen. Sucht man etwas auf den universitären Portal- oder Verwaltungsseiten, ist Google derzeit oft die einzige Suchmaschine, die zu den richtigen Stellen führt.
Aus Privacy-Sicht ist duckduckgo.com fraglos die Suchmaschine der Wahl. Aber sie ist leider eben nicht so effektiv, wie man sich das wünscht. Immerhin ist zumindest ein Großteil der Seiten darüber auffindbar. Für uni-koeln-Ergebnisse aber steige ich hin und wieder temporär auf Google um (beispielsweise im Inkognito-Modus).
Fazit
Wer will, kann etwas dafür tun, weniger transparent im Netz unterwegs zu sein. Letztlich ist das Katz- und Mausspiel des Datensammelns durch die DSGVO zwar nicht völlig ausgeschlossen worden, aber zumindest ist das Thema des Schützens der eigenen (Surf-)Daten den Menschen nun etwas bewusster geworden. Mit dem Interesse wuchsen auch die Anreize für Entwicklungsteams, mit Browsererweiterungen wirksam die Übermittlung von Surfdaten zu unterbinden. So ganz intransparent ist man als User:in natürlich nie, aber zumindest fällt es den Datensammelstellen so etwas schwerer, uns allzusehr zu einem vollständigen Profil zusammenzusetzen.