Als umweltbewusster oder zumindest geiziger Mitarbeiter des Öffentlichen Dienstes verzichtet man in der Regel bei längerer Anfahrt zum Arbeitsplatz auf den privaten PKW und nimmt freudig am öffentlichen Personennahverkehr (ÖPNV) teil. Sprich: Die Deutsche Bahn (und in Köln auch die KVB) ist unser Freund! Gerüchteweise sind die bereitgestellten Verkehrsmittel nicht immer dann vor Ort, wenn man es laut Fahrplan erwarten könnte. Damit man die daraus resultierende Wartezeit nicht am Bahnsteig, sondern am Frühstückstisch bzw. im bequemen Bürosessel verbringen kann, sind aktuelle Informationen über die Verspätungen unerlässlich.
Nun hat sich in der Vergangenheit der Service der DB dahingehend deutlich verbessert. So sind die Verspätungsinformationen inzwischen minutengenau und in Realzeit sowohl im Web als auch mittels der App „DB Navigator“ abrufbar. Der o.g. Mitarbeiter des Ö.D. ist allerdings nicht nur geizig (jaja, und umweltbewusst), sondern auch klickfaul und noch dazu ein Spielkind. So kam ich auf die Idee, sowohl in meinem trauten Heim als auch im Büro mittels ohnehin vorhandener Technik einen (für mich) optimalen Anzeigebildschirm zu basteln.
Dieser sollte nicht nur die aktuellen Verspätungen meiner Zugverbindungen, sondern auch weitere interessante Informationen anzeigen, genauer gesagt: Aktuelle Nachrichten, Wettervorhersage und (zuhause) zusätzlich das Kamerabild einer per WLAN verbundenen IP-Kamera. Als Hardware kamen ein günstiger und dank Notebook-Anschaffung ohnehin kaum noch gebrauchter PC-Bildschirm sowie zeitgemäß ein Raspberry Pi zum Einsatz. Das System sollte in jedem Fall ohne weitere Peripherie, speziell ohne Maus und Tastatur, auskommen. Softwareseitig setzte ich daher auf Google Chrome im Kiosk-Modus. Mittels der Erweiterung „Easy Auto Refresh“ kann man dafür sorgen, dass Chrome die angezeigte Seite automatisch einmal pro Minute neu lädt. Das Kamerabild läuft ohnehin im Streaming-Mode.
Der graphische Desktop des Raspi musste so eingestellt werden, dass er sich nicht automatisch abschaltet. Die Kontrolle über die Anzeige sollte ausschließlich per Ein/Aus-Knopf des Monitors ablaufen. Dies erreicht man über die eine Einstellung in LightDM.
Da ich mir die Installation und Konfiguration eines Webservers sparen wollte, verwende ich eine einfache lokale HTML-Seite auf dem Raspi. Die beiden gewünschten Elemente „Aktuelle Nachrichten“ und „Wettervorhersage“ sind sehr leicht über passende Widgets realisierbar. Ich habe hierzu die Angebote von wetterdienst.de und rp-online genutzt, es gibt jedoch zahlreiche weitere Anbieter.
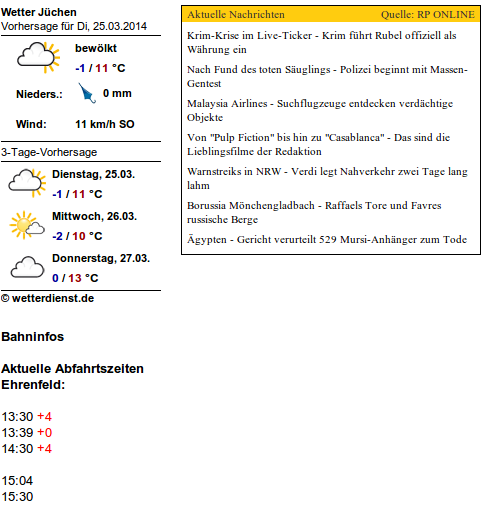
Richtig interessant wurde es dann bei der Einbindung der Verspätungsanzeige. Wie ich feststellen musste, bietet die Bahn leider keine geeignete API zu diesem Zweck. Mir blieb nichts anderes übrig als die entsprechende Webseite zu parsen. Diese Erkenntnis war die Geburtsstunde von Projekt „Mepevea“ (MEin PErsönlicher VErspätungsAnzeiger).
Wie erwähnt wollte ich auf die Installation und den Betrieb eines Webservers verzichten. Die Anzeige soll ja ohnehin nur für mich persönlich laufen. Daher musste ich die eigentliche Logik nebst Parser in ein Pythonskript packen, welches per Cronjob aufgerufen wird (ja, ich arbeite unter Linux und ignoriere Windows seit Jahren – die Portierung sollte aber kein großes Problem darstellen). Als Basismodul für den Parser dient natürlich „BeautifulSoup“, darüber hinaus werden urllib zum Abruf der Seite und einige weitere Module benötigt. Der Start lautet also:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import bs4, urllib2, time, fileinput, sys, urllib„fileinput“ verwende ich, um später den <div>-Block im HTML durch die korrekten Daten auszutauschen, z.B.:
for line in fileinput.FileInput("/home/pi/anzeige/bahnlinks.html",inplace=1):
if line.startswith('<div id="bahn">'):
line = text
sys.stdout.write(line)Natürlich macht es Sinn, abhängig vom Wochentag und der Tageszeit die Anzeige zu variieren (Hinfahrt, Rückfahrt, Abend/Wochenende), also z.B.:
timestamp = time.localtime(time.time())
if timestamp[6] > 4:
textlist.append("<b>Bahnanzeige erst am Montag wieder! Schönes Wochenende!</b>")Hier wird schon klar: Individuelle Anpassung ist unerlässlich und ich kann die Beispiele nur anreißen. Keine Sorge: Am Ende werde ich als „großes Beispiel“ mein komplettes Skript bereitstellen.
Zentrales Element des Skriptes ist die Parserfunktion. Sie erhält als Parameter die URL der Bahn (dazu später) und jagt sie durch BeautifulSoup:
def parser(url):
page = urllib2.urlopen(url).read()
soup = bs4.BeautifulSoup(page)Man möge mir an dieser Stelle glauben, dass wir die spannenden Inhalte erhalten, wenn wir nach den Keywords, genauer gesagt den <td>-Klassen „overview timelink“ und „overview tprt“ suchen:
zeilen = soup.find_all('td', {"class" : "overview timelink"})
verspaetungen = soup.find_all('td', {"class" : "overview tprt"})Schon hier erkannt man, wo das größte Problem unserer schönen Bastelei liegt: Sollte die Bahn die Klassennamen aus irgendwelchen Gründen ändern, funktioniert natürlich nichts mehr. Das gleiche gilt für die URLs und die HTML-Struktur. Genau aus diesem Grund gibt es ja i.d.R. kapselnde APIs, aber die stehen hier wie gesagt nicht zur Verfügung.
Standardmäßig erhält man von der Bahn die nächsten drei Züge ab dem definierten Zeitpunkt. Ich habe die finale Version noch so erweitert, dass man dies variieren kann, aber das würde hier zu weit führen. Ebenso müsste ich nun eigentlich auf die Details von BeautifulSoup eingehen, um den folgenden Codeblock zu erläutern. Aber auch dies möchte ich mir sparen und auf die gute Online-Dokumentation des Moduls verweisen. Unsere Verbindungen sowie die aktuellen Verspätungen erhalten wir so:
parsedtext = ''
zaehler = 0
for zeile in zeilen:
for zelle in zeile.children:
parsedtext += zelle.contents[0]
parsedtext += '<span style="color: red;">'
for verspaetung in verspaetungen[zaehler].children:
if str(verspaetungen[zaehler]).count("okmsg") > 1 or str(verspaetungen[zaehler]).count("red") > 1:
parsedtext += verspaetung.contents[0]
break
parsedtext += '</span>'
zaehler += 1Ich bin mir zu 99% sicher, dass dies nicht die eleganteste Version ist, um die Informationen zu erhalten und aufzubereiten. Aber sie funktioniert. Wer das Ganze kürzer, schöner und verständlicher hinbekommt, ohne dass die Funktionalität leidet, möge sich bei mir melden.
Kommen wir nun zu den benötigten URLs. In einer ersten Version hatte ich pro Zug eine URL auf Basis des Bahntools „query2.exe“ verwendet, die auch deutlich einfacher zu parsen war (Anmerkung: Bitte von der Endung „.exe“ nicht täuschen lassen: Es handelt sich um einen Webservice, nicht um ein lokales Programm.). Leider musste ich feststellen, dass die Bahn bei jeder (geplanten) Mini-Fahrplanänderung die URL komplett verändert. Auf Dauer war das also leider keine Lösung. Stattdessen verwende ich nun die „Vorstufe“ namens „query.exe“. Diese hat klar definierte und – hoffentlich – dauerhaft beständige Parameter. Als Parameter benötigen wir den Code des Startbahnhofs, den Code des Zielbahnhofs und die Startzeit.
Während die Startzeit natürlich jedem selbst überlassen bleibt und einfach in der Form hh:mm verwendet wird, muss man sich die Codes (sog. IBNR) der Bahnhöfe einmalig heraussuchen. Dies geht zum Glück sehr einfach mittels einer Onlinesuche.
Lautet die IBNR des Startbahnhofs bspw. 8000208, die des Zielbahnhofs 8000133 und die gewünschte Startzeit ist 17:00 Uhr, lautet die gesuchte URL:
http://reiseauskunft.bahn.de/bin/query.exe/dox?S=8000208&Z=8000133&time=17:00&start=1Damit lässt sich nun für jede beliebige Verbindung und Kombination von Tageszeiten ein passender Anzeiger (eben ein „Mepevea“) bauen.
Für weitere Ideen, Verbesserungsvorschläge etc. bin ich jederzeit dankbar. Und wenn jemand die Bahn überreden könnte, doch mal eine entsprechende API bereitzustellen, das wäre ein Traum. 😉
Wie versprochen: Den vollständigen Text des Skriptes sowie eine Beispiel-HTML-Seite findet man unter http://dl.distinguish.de/mepevea.zip