Bei meinem letzten Beitrag zum Thema hatte ich schon beschrieben, wie man den Arduino mit Hilfe eines E32-Shields ins WLAN bringt. Nun sollte das Ganze einen nützlichen Zweck erfüllen. Für den Anfang reichte mir der Anschluss eines einfach DS18B20-Temperatursensors und die fortlaufende Dokumentation der Messung bei einem IoT-Server. Natürlich kann man auch selbst einen MQTT-Server (sprich: Mosquito-Server) aufsetzen und verwenden, aber ThingSpeak bietet sich hier einfach aus mehreren Gründen an. Vor allem auch deshalb, weil es bereits eine fertige Bibliothek für den Arduino gibt, sodass man die Befehle zum Senden der Werte auf einem hohen Abstraktionslevel belassen kann.
Wie so oft gilt auch hier: Natürlich gibt es das alles schon und es ist auch alles im Netz frei verfügbar und dokumentiert. Aber es kostet dann doch relativ viel Aufwand, alles zusammen zu tragen und im Detail zu verstehen. Daher schreibe ich meine Vorgehensweise hier strukturiert auf. Ebenfalls gilt: Natürlich braucht der wahre Profi den Arduino gar nicht dafür, ein kleiner ESP8266 genügt ebenso. Aber es geht ja auch ein wenig um den Spaß und um das Verständnis des Ganzen, und dafür ist der Arduino einfach besser geeignet. Natürlich wäre das Gleiche auch mit einem Raspberry Pi machbar, der große Vorteil hier liegt darin, dass man sich ein schönes Python-MQTT-Skript schreiben kann und die Fallen vom Arduino-C etwas umschifft.
Doch zurück zum Arduino-Beispiel. Die Verkabelung der Hardware ist – basierend auf der bereits bestehenden Kombination aus Arduino und ESP-Shield – denkbar einfach. Der Temperatursensor bringt drei Kabel mit, die an 3,3V- (rot), GND- (schwarz) und einen beliebigen Digital-PIN (gelb) des Arduino bzw. des aufgesteckten Shields angeschlossen werden. Fertig.
Die eigentliche Kunst liegt also in der Software. Als Basis nehme ich den verkürzten Sketch aus dem WLAN-Anschluss-Beispiel:
#include "WiFiEsp.h"
#include "SoftwareSerial.h"
SoftwareSerial Serial1(3, 2); // RX, TX
char ssid[] = "MeinTollesWLAN";
char pass[] = "**********";
int status = WL_IDLE_STATUS;
WiFiEspClient client;
void setup(void) {
Serial.begin(9600);
Serial1.begin(9600);
WiFi.init(&Serial1);
while ( status != WL_CONNECTED) {
Serial.print("Verbindungsaufbau zu ");
Serial.println(ssid);
status = WiFi.begin(ssid, pass);
}
Serial.println("Verbindung hergestellt!");
Serial.println();
printWLAN();
Serial.println();
}
void loop(void) {
}
void printWLAN()
{
IPAddress ip = WiFi.localIP();
Serial.print("IP-Adresse: ");
Serial.println(ip);
Serial.print("SSID: ");
Serial.println(WiFi.SSID());
long rssi = WiFi.RSSI();
Serial.print("Signalstaerke (RSSI): ");
Serial.println(rssi);
}
Wie man leicht sieht, macht der Sketch vorerst nichts abgesehen vom Verbindungsaufbau zum WLAN. Soweit so gut. Beginnen wir mit den Bibiotheken und Konstanten, die wir für alles Weitere benötigen. Die Bibliotheken heißen „OneWire“ (Temperatursensor) und „ThingSpeak“ (Verbindung zum IoT-Server).
ThingSpeak kann man auf der folgenden Seite herunterladen und dann der (sehr kurzen) Installationsanleitung folgen:
https://github.com/mathworks/thingspeak-arduino
Und wenn man gerade schon dabei ist, verfährt man ebenso mit der hier erhältlichen OneWire-Library.
Welche Konstanten werden nun benötigt? Zum einen die Nummer des PINs, an dem das gelbe Datenkabel des Sensors angeschlossen wurde. In meinem Beispiel ist das die Nr. 5. Um mit ThingSpeak arbeiten zu können, muss zudem ein Account bei dem Dienst angelegt werden. Nach dem Login kann dann ein einzelner Channel erstellt werden, der künftig die Daten entgegen nimmt. Die Nummer des Channels sowie unser APIKey von ThingSpeak sind die letzten benötigten Konstanten:
#include "OneWire.h"
#include "ThingSpeak.h"
int Sensor_Pin = 5;
unsigned long Channel = 123456789abcdef;
const char * APIKey = "************";
Bei unserer Messung verwenden wir ein Objekt aus der Klasse OneWire, dem als Parameter die Nummer des PINs übergeben wird:
OneWire ds(Sensor_Pin);
In der setup-Funktion wird die Kommunikation mit dem ThingSpeak-Server initialisiert, dabei wird die WLAN-Verbindung als Übertragungsweg übergeben:
ThingSpeak.begin(client);
Kommen wir zur Loop-Funktion. Diese soll im Grunde folgende Elemente enthalten: Messen, Ausgeben, Übertragen, Warten. Das Messen ist dabei mit riesigem Abstand die komplexeste Aufgabe und wird daher in eine eigene Funktion „getTemp“ ausgelagert. Der Rest ist relativ einfach. Damit nur echte Messwerte eingetragen werden, verwende ich „-100“ als Fehlerwert, alles darüber hinaus wird an ThingSpeak übertragen. Dabei müssen Channel, das Datenfeld (in unserem Fall einfach das einzige, also 1), der gemessene Wert sowie der APIKey übertragen werden. ThingSpeak kann man nicht mit beliebig vielen Werten fluten, 20 Sekunden Wartezeit zwischen den Messungen sind hier i.d.R. angemessen. Somit ergibt sich die Loop-Funktion:
void loop(void) {
float temperatur = getTemp();
Serial.println(temperatur);
if ( temperatur > -100) {
ThingSpeak.writeField(Channel, 1, temperatur, APIKey);
}
delay(20000);
}
Tja, und nun geht’s ans Eingemachte, namentlich um die Funktion „getTemp“. Ich gebe zu, dass ich – der ich nie wirklich C gelernt habe – dann doch einige Zeit intensiv darüber nachdenken musste, um die gefundenen Programmierbeispiele zu verstehen. Ich habe sie hier auf das Nötigste gekürzt und versuche sie zu erläutern.
Wir benötigen zwei Byte-Arrays namens „addr“ (für die Adressdaten des Sensors, es könnte mehrere geben) und „data“ (für die Messwerte). Zudem gilt es, ein paar Fehler abzufangen, z.B. Fehler in der Prüfsumme (CRC) oder gar einen nicht gefundenen oder nicht unterstützten Adapter. In all diesen Fällen wird unser Fehlerwert „-100“ zurückgegeben:
byte data[12];
byte addr[8];
if ( !ds.search(addr)) {
ds.reset_search();
return -100;
}
if ( OneWire::crc8( addr, 7) != addr[7]) {
Serial.println("CRC fehlerhaft!");
return -100;
}
if ( addr[0] != 0x10 && addr[0] != 0x28) {
Serial.print("Kein Sensor erkannt");
return -100;
}
Durch den Aufruf von „ds.search(addr)“ wird der Array praktischerweise direkt mit den Adressdaten des Sensors gefüllt, sodass wir nun – da keine Fehler aufgetreten sind – damit arbeiten können. Die nächsten Schritte sind im Einzelnen: Reset der Kommunikation, Auswahl des Sensors, Durchführen einer Messung und schließlich das Auslesen der Werte aus einem Zwischenspeicher, Speichern der Werte in unserem Datenarray. Anschließend kann wieder ein Reset der Suche nach Sensoren erfolgen.
ds.reset();
ds.select(addr);
ds.write(0x44); // Kommando: Messung durchfuehren
ds.reset();
ds.select(addr);
ds.write(0xBE); // Kommando: Werte auslesen
for (int i = 0; i < 9; i++) {
data[i] = ds.read();
}
ds.reset_search();
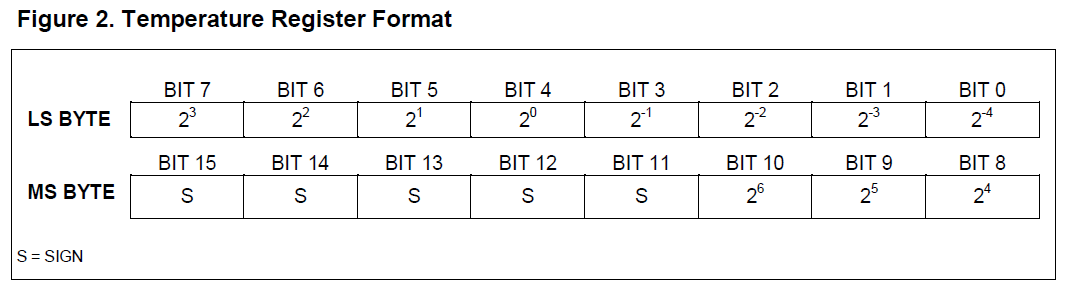
Fast fertig. Doch unsere Messwerte sind noch ein wenig „kryptisch“ und entsprechen nicht gerade dem, was wir aufzeichnen wollen. Die eigentlich interessanten Werte „MSB“ (most significant byte) und „LSB“ (least significant byte) stecken in unseren Datenfeldern 1 bzw. 0:
byte MSB = data[1];
byte LSB = data[0];
Sie enthalten die gemessene Temperatur in Binärdarstellung, wie ein Blick in das Datenblatt des DS18B20 verrät:
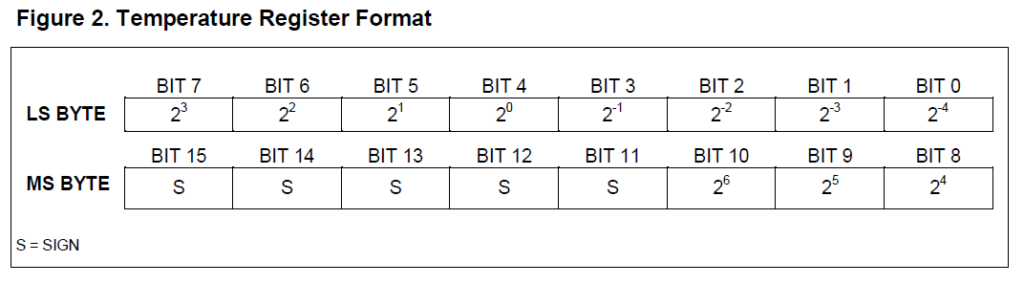
Um daraus nun einen „gewohnten“ Temperaturwert zu erhalten, bedarf es einer bitweisen Verschiebung des MSB um 8 Stellen nach links und einer bitweisen Verknüpfung mit dem LSB (und gleichzeitig einer Umwandlung in eine Fließkommazahl zur Basis 10):
float tempRead = ((MSB << 8) | LSB);
Wie man dem Datenblatt entnehmen kann, enthält das Ganze aber auch Nachkommastellen, das wurde bei der Umwandlung nicht berücksichtigt. Durch welche Zahl muss nun geteilt werden? Da unsere eigentliche „Basis“ (die 2^0 – Stelle) an vierter Position befindet, ist die Zahl um den Faktor 2^4 = 16 zu hoch. Es folgt:
float TemperatureSum = tempRead / 16;
return TemperatureSum;
Fertig! Hier noch einmal der komplette Sketch, viel Spaß beim Ausprobieren:
#include "OneWire.h"
#include "ThingSpeak.h"
#include "WiFiEsp.h"
#include "SoftwareSerial.h"
int Sensor_Pin = 5;
unsigned long Channel = 123456789abcdef;
const char * APIKey = "************";
OneWire ds(Sensor_Pin);
SoftwareSerial Serial1(3, 2); // RX, TX
char ssid[] = "MeinTollesWLAN";
char pass[] = "**********";
int status = WL_IDLE_STATUS;
WiFiEspClient client;
void setup(void) {
Serial.begin(9600);
Serial1.begin(9600);
WiFi.init(&Serial1);
ThingSpeak.begin(client);
while ( status != WL_CONNECTED) {
Serial.print("Verbindungsaufbau zu ");
Serial.println(ssid);
status = WiFi.begin(ssid, pass);
}
Serial.println("Verbindung hergestellt!");
Serial.println();
printWLAN();
Serial.println();
}
void loop(void) {
float temperatur = getTemp();
Serial.println(temperatur);
if ( temperatur > -100) {
ThingSpeak.writeField(Channel, 1, temperatur, APIKey);
}
delay(20000);
}
float getTemp(){
byte data[12];
byte addr[8];
if ( !ds.search(addr)) {
ds.reset_search();
return -100;
}
if ( OneWire::crc8( addr, 7) != addr[7]) {
Serial.println("CRC fehlerhaft!");
return -100;
}
if ( addr[0] != 0x10 && addr[0] != 0x28) {
Serial.print("Kein Sensor erkannt");
return -100;
}
ds.reset();
ds.select(addr);
ds.write(0x44); // Kommando: Messung durchfuehren
ds.reset();
ds.select(addr);
ds.write(0xBE); // Kommando: Werte auslesen
for (int i = 0; i < 9; i++) {
data[i] = ds.read();
}
ds.reset_search();
byte MSB = data[1];
byte LSB = data[0];
float tempRead = ((MSB << 8) | LSB);
float TemperatureSum = tempRead / 16;
return TemperatureSum;
}
void printWLAN()
{
IPAddress ip = WiFi.localIP();
Serial.print("IP-Adresse: ");
Serial.println(ip);
Serial.print("SSID: ");
Serial.println(WiFi.SSID());
long rssi = WiFi.RSSI();
Serial.print("Signalstaerke (RSSI): ");
Serial.println(rssi);
}